How graphs can be used in AI
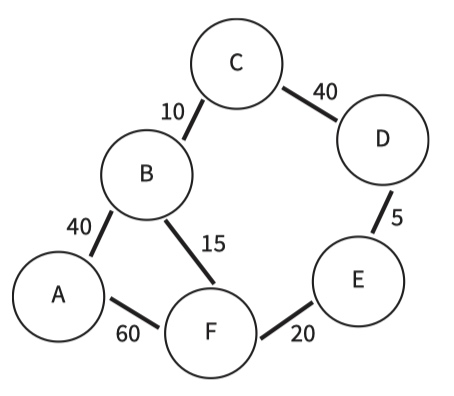
A graph is a collection of nodes or vertices between which there can be edges. Each node has a name. An edge can have an associated label which is a numerical value.
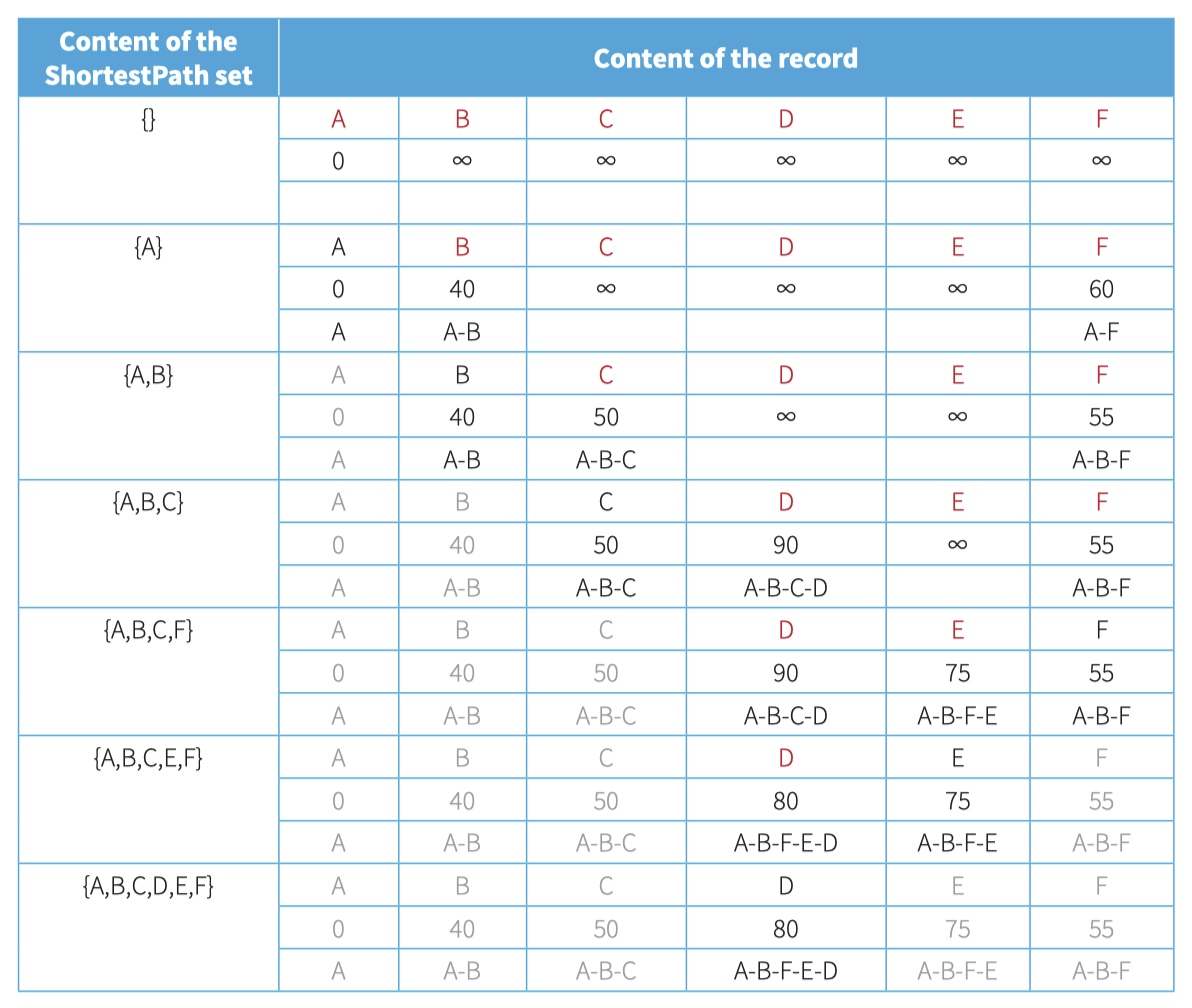
Nodes represent places and the edge labels represent the distances between those places.
Edges are only included in the graph when there is a route available for direct travel between the pair of nodes.
| path | distance |
|---|---|
| For A to B to C to D | overall distance is 40 + 10 + 40 = 90 |
| For A to B to F to E to D | overall distance is 40 + 15 + 20 + 5 = 80, which is the shortest |
| For A to F to E to D | overall distance is 60 + 20 + 5 = 85 |
| For A to F to B to C to D | overall distance is 60 + 15 + 10 + 40 = 125 |
Dijkstra 算法
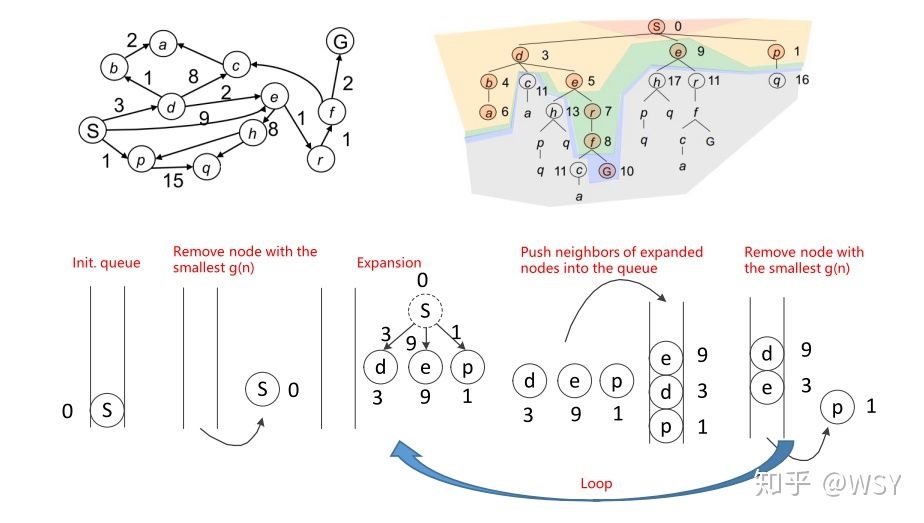
Dijkstra算法是典型最短路算法,用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。
大概过程:
创建两个表,OPEN, CLOSE。
OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。
1. 访问路网中里起始点最近且没有被检查过的点,把这个点放入OPEN组中等待检查。
2. 从OPEN表中找出距起始点最近的点,找出这个点的所有子节点,把这个点放到CLOSE表中。
3. 遍历考察这个点的子节点。求出这些子节点距起始点的距离值,放子节点到OPEN表中。
4. 重复2,3,步。直到OPEN表为空,或找到目标点。
Dijkstra 和 A* 算法比较
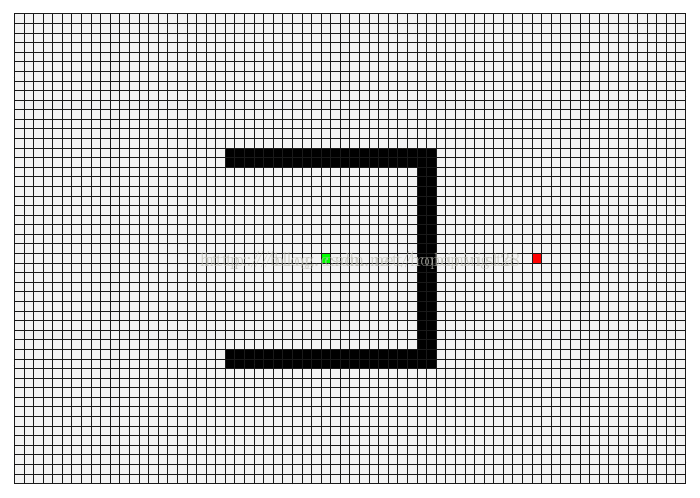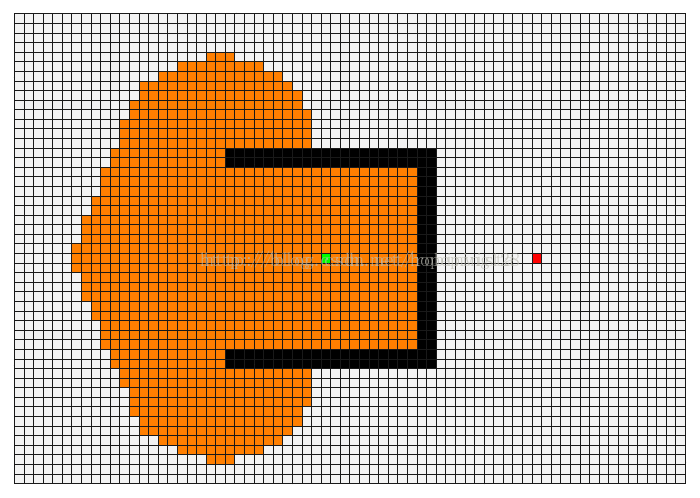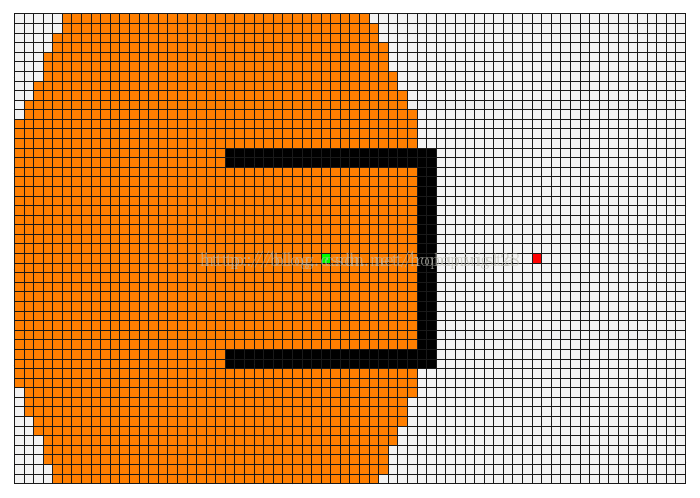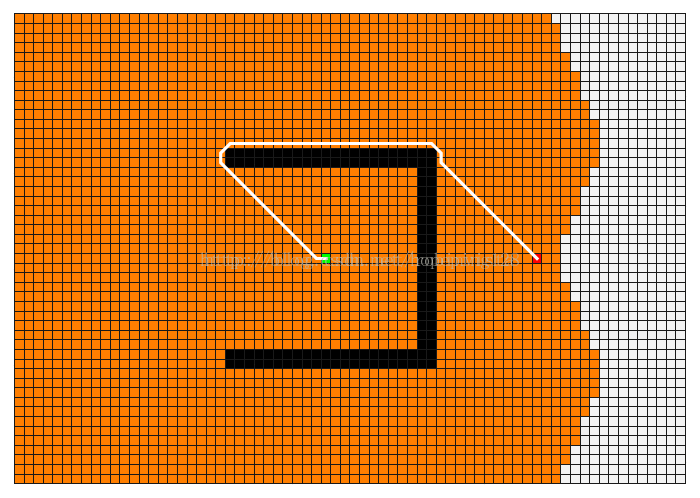
dijkstra 算法
A* 算法
- Dijkstra算法计算源点到其他所有点的最短路径长度,A*关注点到点的最短路径(包括具体路径)。
- Dijkstra算法建立在较为抽象的图论层面,A*算法可以更轻松地用在诸如游戏地图寻路中。
- Dijkstra算法的实质是广度优先搜索,是一种发散式的搜索,所以空间复杂度和时间复杂度都比较高。对路径上的当前点,A*算法不但记录其到源点的代价,还计算当前点到目标点的期望代价,是一种启发式算法,也可以认为是一种深度优先的算法。
- 由第一点,当目标点很多时,A*算法会带入大量重复数据和复杂的估价函数,所以如果不要求获得具体路径而只比较路径长度时,Dijkstra算法会成为更好的选择。
Regression analysis methods
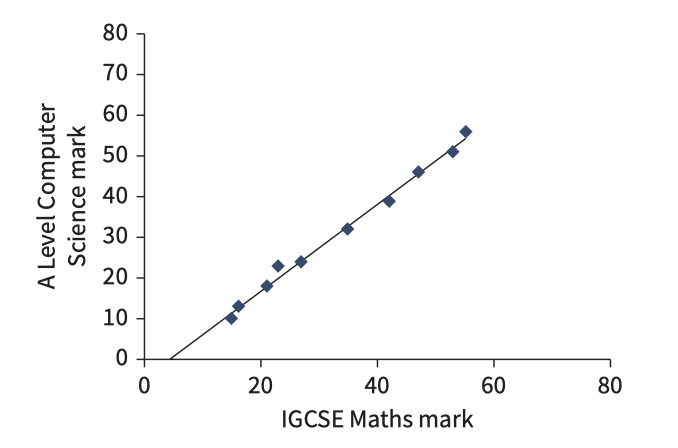
In some applications the aim of the AI is to predict and provide, as output numerical values for some defined quantity, on the basis of data values for different quantities that have been input to the AI algorithm.
The simplest application of regression analysis is when values for only one quantity are to be input and when a linear relationship is expected between these values and the values to be predicted.
Neural networks
Artificial neural networks should be considered as a foundation for artificial intelligence systems.
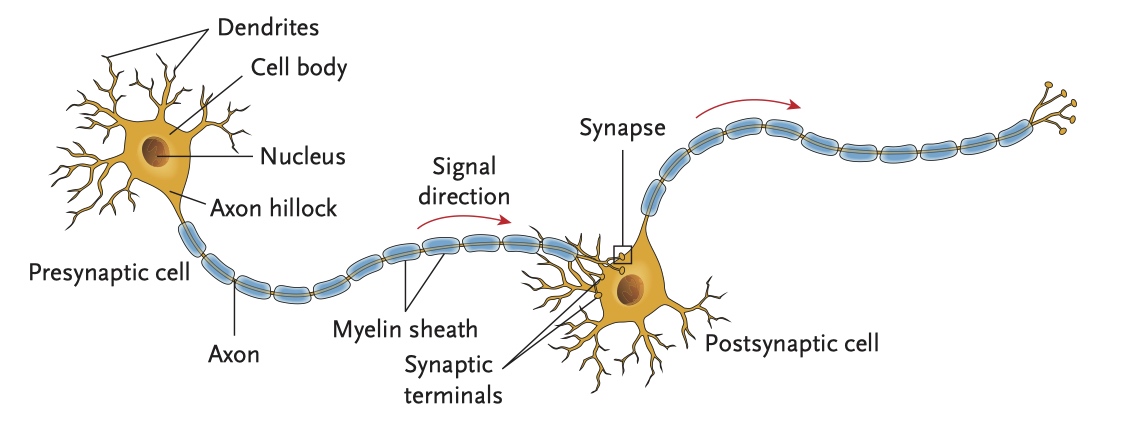
Neural networks
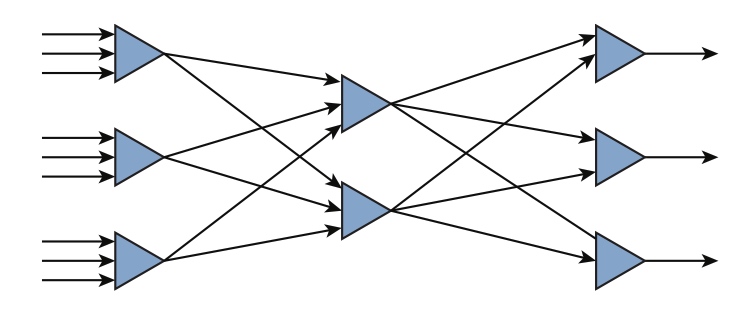
schematic representation