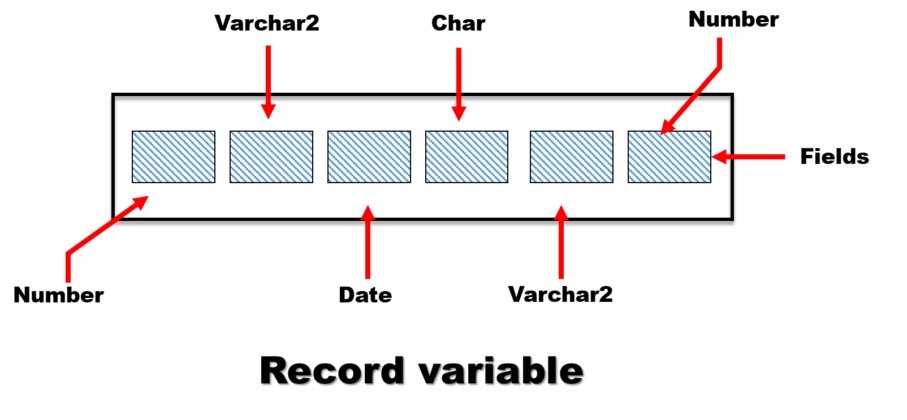
Composite user-defined data types
DECLARE
TYPE <type_name> IS RECORD
(
<column1> <datatype>,
...
...
)
A composite user-defined data type has a definition with reference to at least one other type.
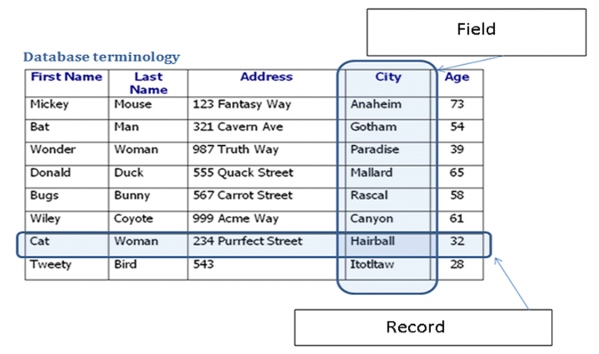
- The record data type
- This allows the programmer to create record data types with components that precisely match the data requirements of the particular program.
- Python is a language that does not support the use of a record data type.
- The class
- A class is a data type which is used for an object in object-oriented programming.

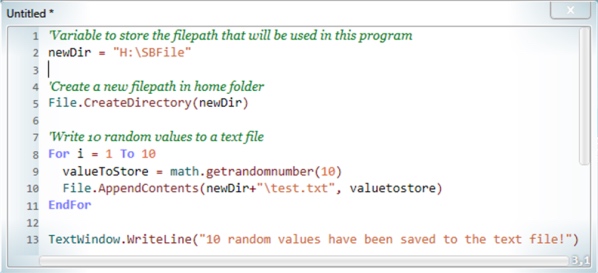
Serial files
A serial file contains records that have not been organised in any defined order.
A serial file is a database that stores values as a series of items, one after the other
Sequential files
A sequential file has records that are ordered.
A sequential file stores data in some sort of order, perhaps based on an account number
toring data in a Sequential files mean that you can run binary searches.
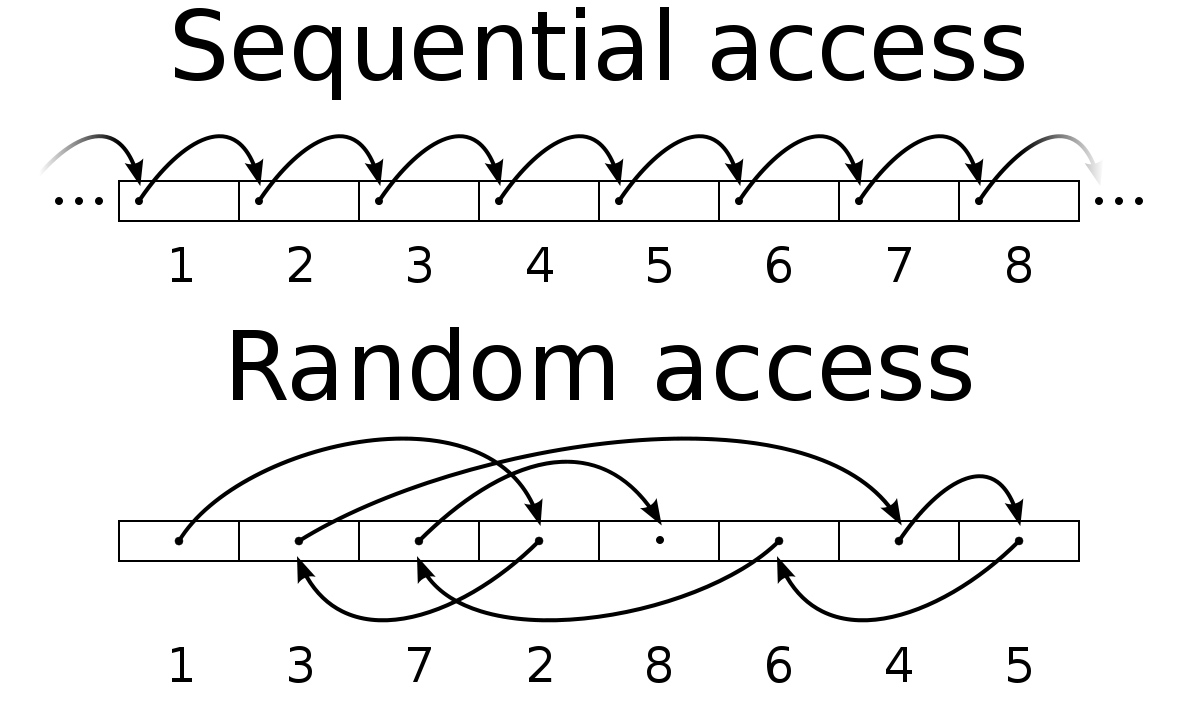
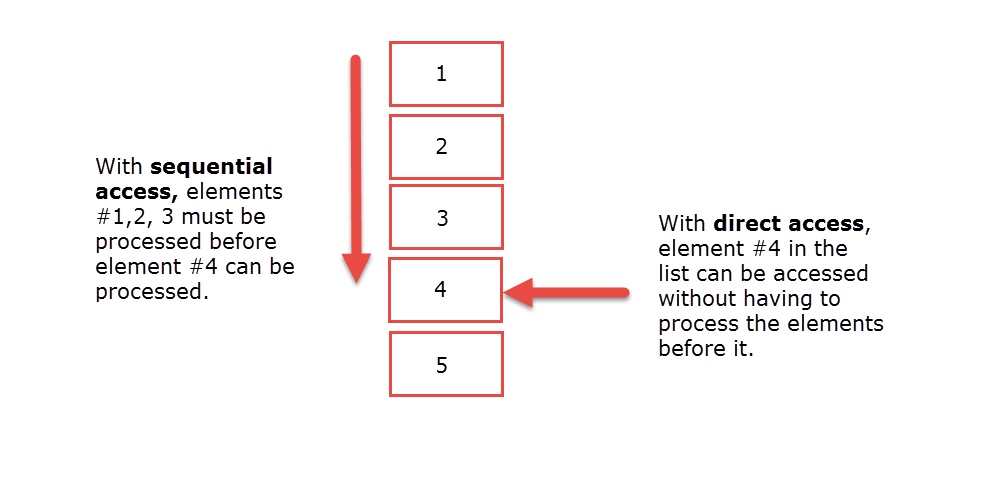
Random access is also known as direct access.
For simplicity this can be illustrated for 4-digit values in the key field where 1000 is used for the dividing number. The following represent three calculations:
0045/1000 gives remainder 45 for the address in the file
2005/1000 gives remainder 5 for the address in the file
3005/1000 gives remainder 5 for the address in the file
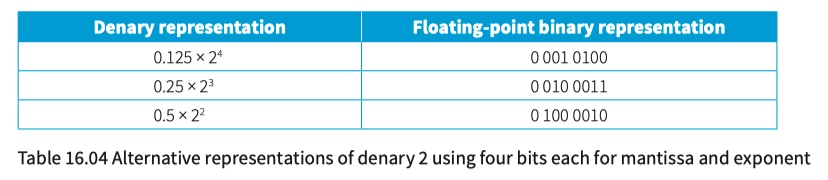
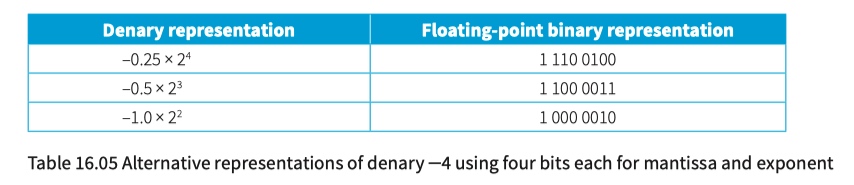
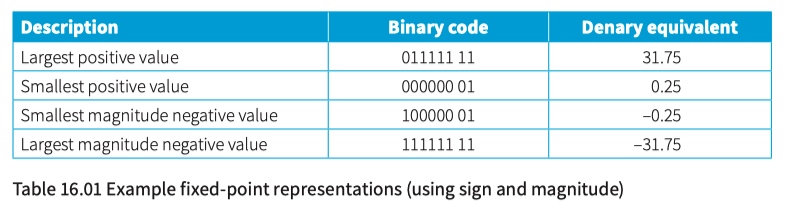
Floating-point and fixed-point representations
floating-point representation
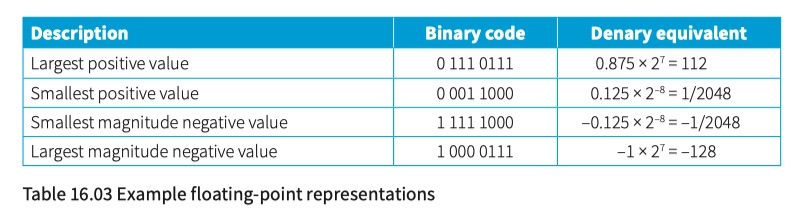
\pm M - significand or mantissa
E - exponent or exrad
R - radix
fixed-point representation
Precision and normalisation
You have to decide about the format of a floating-point representation in two respects. You have to decide the total number of bits to be used and decide on the split between those representing the mantissa and those representing the exponent.