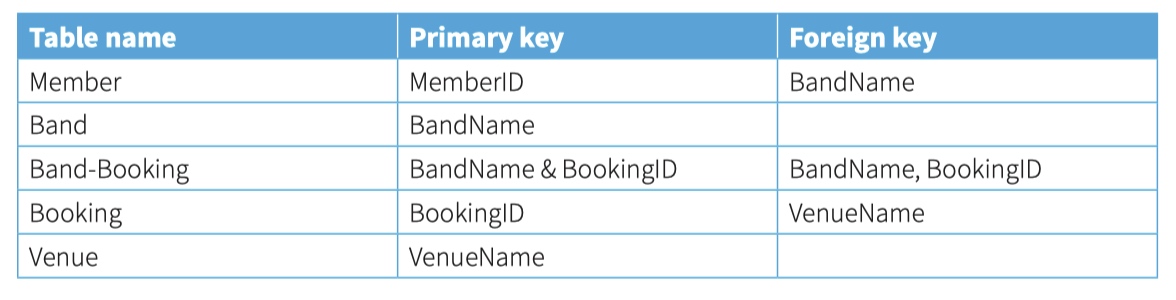
txt -> csv -> excel -> database
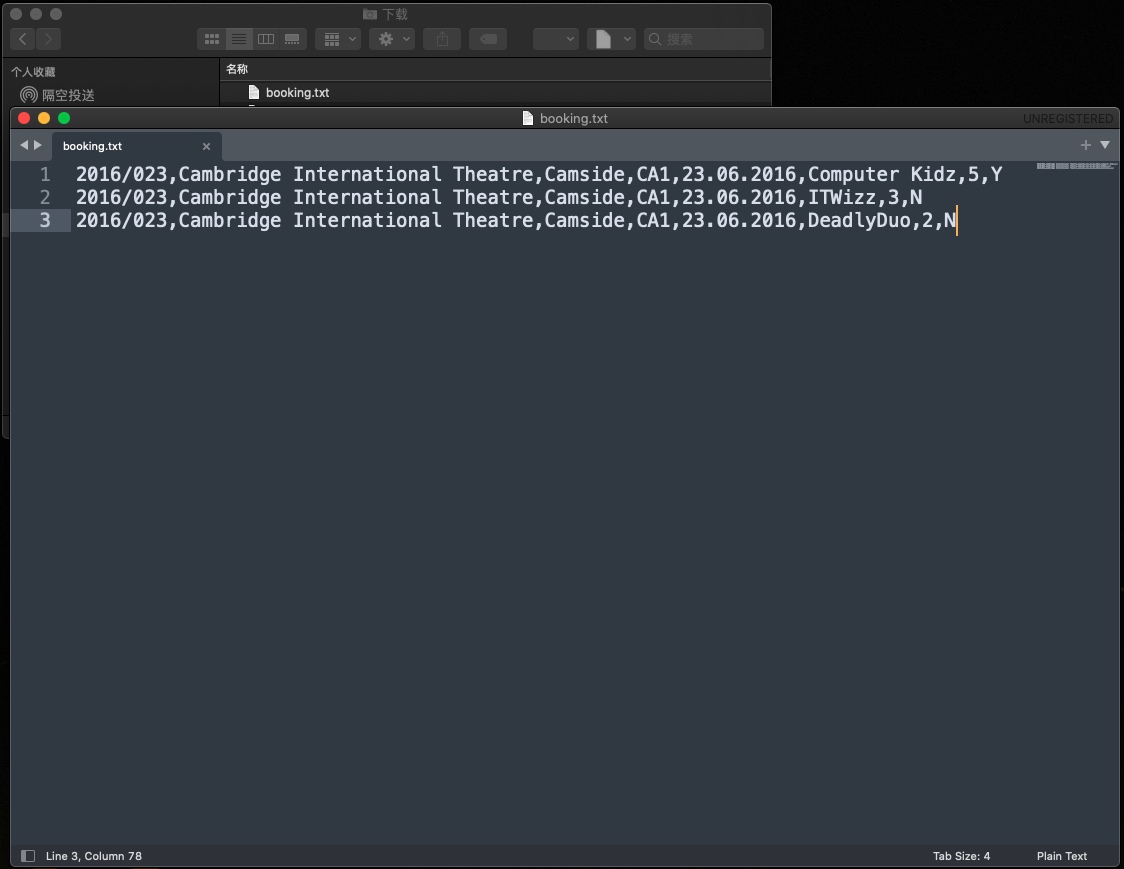
txt file
CSV file
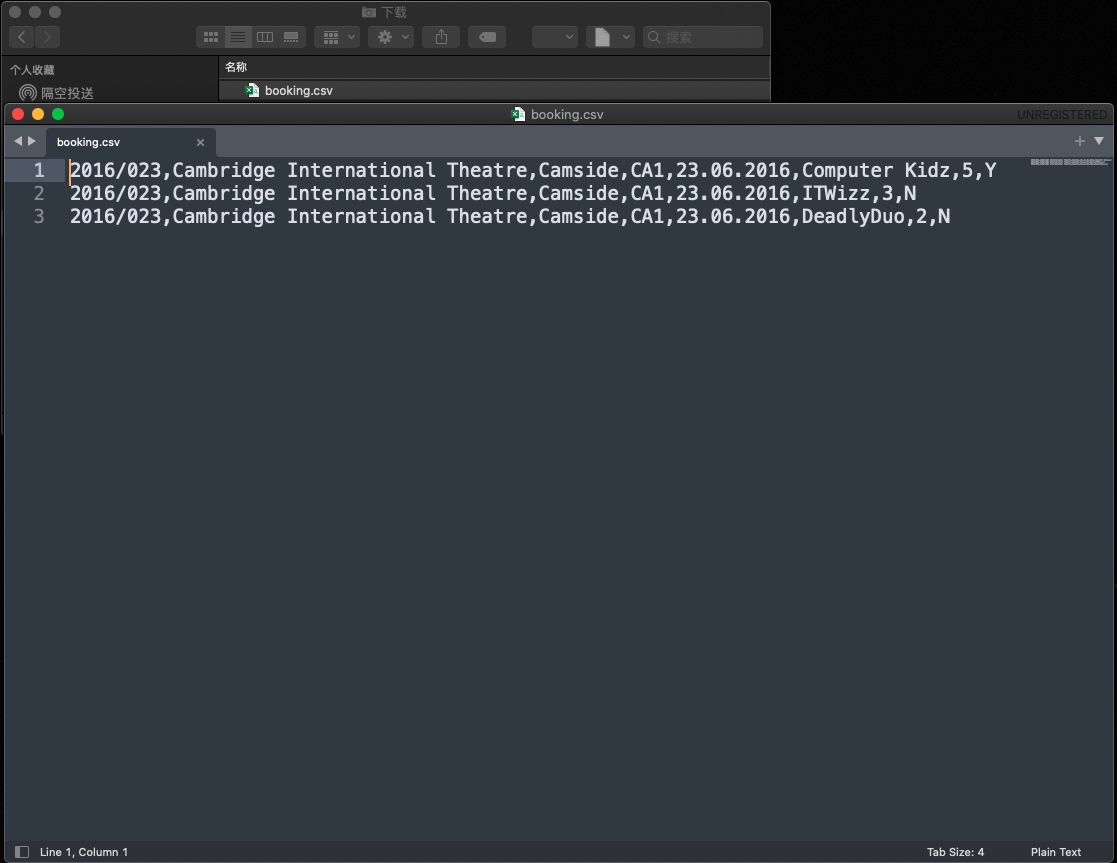
excel file - open csv by excel
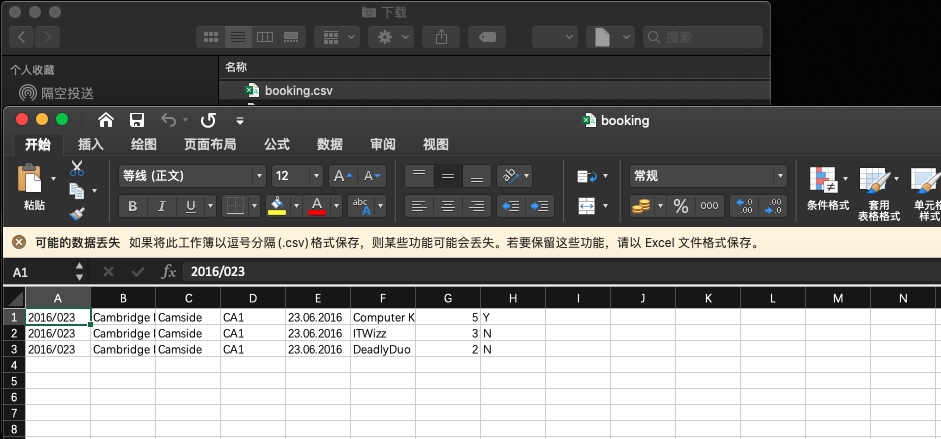
Database
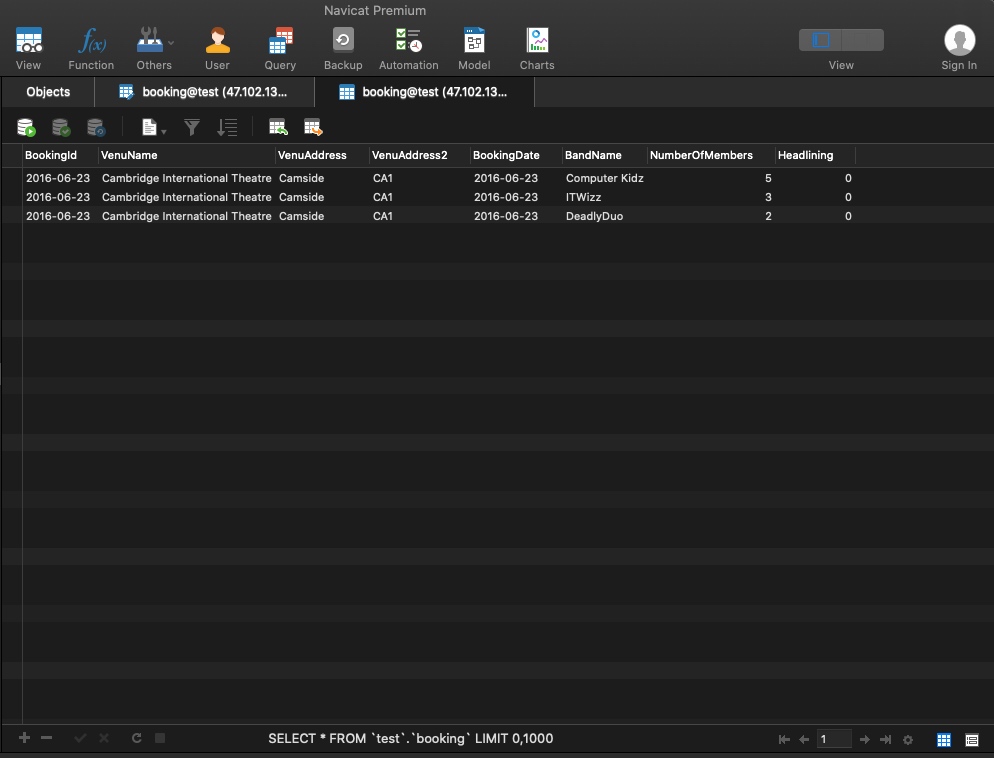
存在的问题
- incorrect data - 文件无法限制具体年月日类型,也无法控制会员数量,可能写错为a
- BandName 用户可以随便输入,无法限制指定的BandName。所以可能输入了不存在的
- wrong order - 文件系统无法对会员数进行排序
- The data privacy issue with a single file - 安全问题,任何人都可以查看txt文件
- data redundancy - 数据冗余
The relational database
In the relational database model, each item of data is stored in a relation which is a special type of table. A relational database is a collection of relational tables.
In a database design, a table would be given a name with the attribute names listed in brackets after the table name.
Member(MemberID, MemberGivenName, MemberFamilyName, BandName, ...) Band(BandName, AgentID, ...)
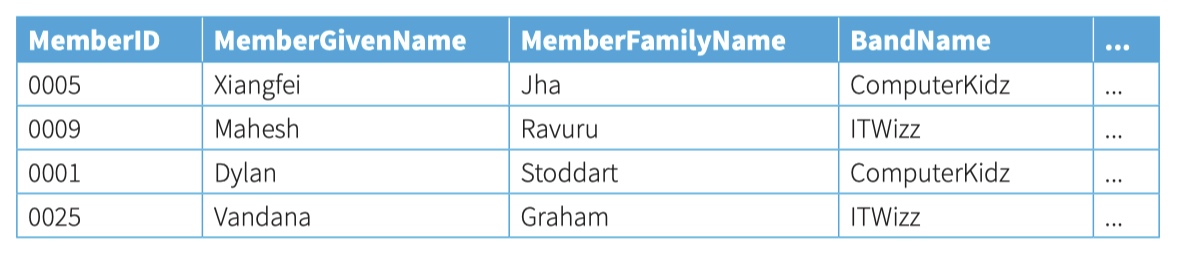
modelling
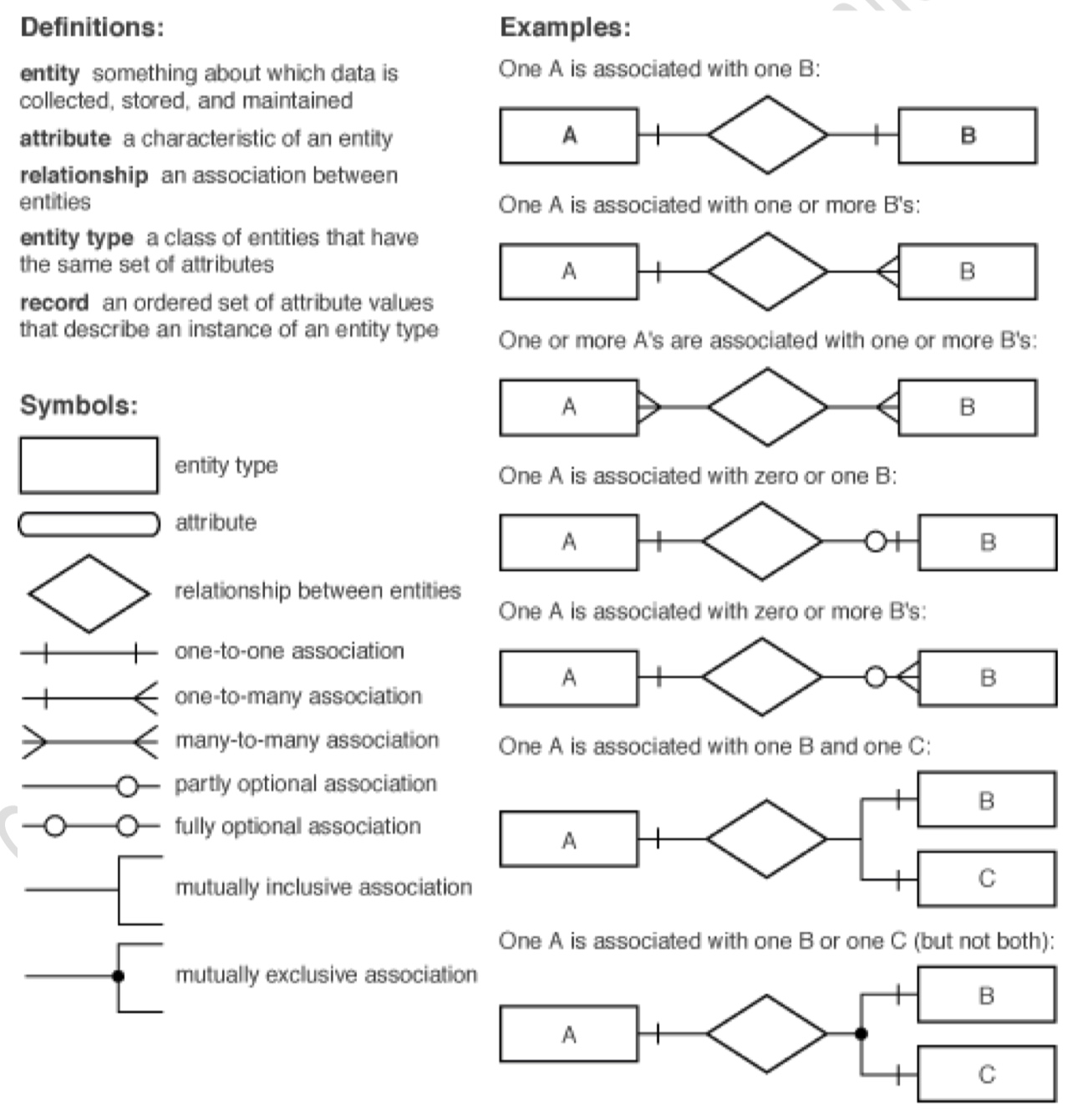
Step 2: Identify the relationships
This requires experience, but the aim is not to define too many. You choose the following three::
- Booking with Venue
- Booking with Band
- Band with Member.

Step 3: Decide the cardinalities of the relationships
- one-to-one or 1:1
- one-to-many or 1:M
- many-to-one or M:1
- many-to-many or M:M.

The M:1 relationship between Member and Band. One Band has more than one Member so it has many.

The M:1 relationship with more detail. A member must belong to a Band and a Band must have more than one Member.

The M:1 relationship between Booking and Venue. One Booking is for one Venue (there must be a venue and there cannot be more than one) and that one Venue can be used for many Bookings so the relationship between Booking and Venue is M::1. A Venue might exist that has so far never had a booking.

The M:M relationship between Band and Booking. One Booking can be for many Bands and that one Band has many Bookings.

The E–R diagram for the theatrical agency’s booking database
A logical entity–relationship model
A link entity inserted to resolve a M::M relationship 
1:M - have a foreign key referencing the primary key of the entity at the one end. M:M - Another way of looking at this problem is to argue that a foreign key is required in each entity but neither table could be created first because the other table needed to exist for the foreign key to be defined. The solution for the M::M relationship is to create a link entity.
范式
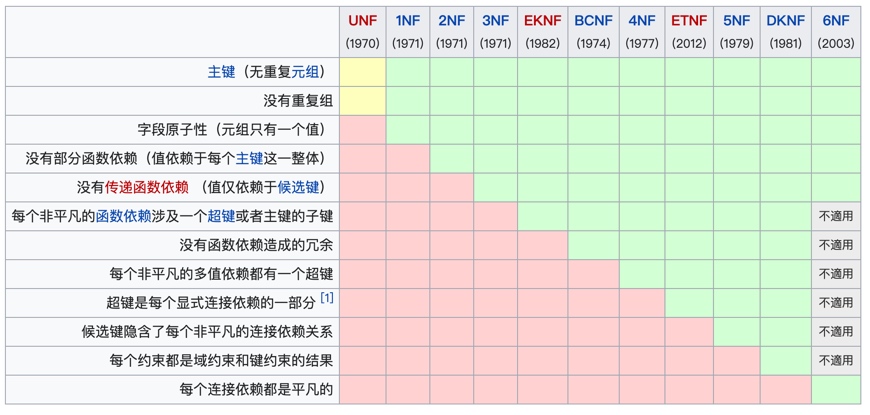
1、第一范式(1NF) 所谓第一范式(1NF)是指在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。简而言之,第一范式就是无重复的域。
范式
2、第二范式(2NF) 在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复,无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。(该主键的添加是在ER设计时添加,不是建库时随意添加)
范式
3、第三范式(3NF) 在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖) 第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性,也就是在满足2NF的基础上,任何非主属性不得传递依赖于主属性。
一范式 (原子性)
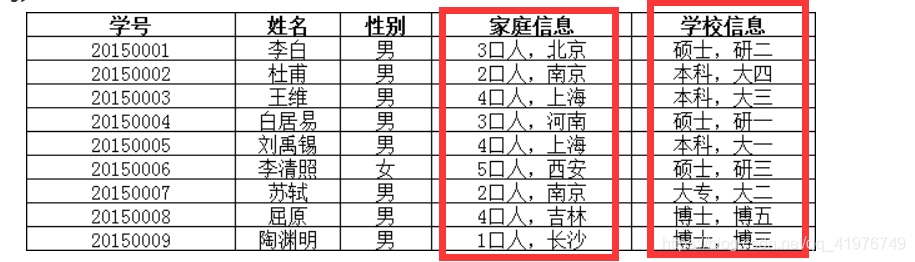
字段为 ' 家庭信息 ' 和 '学校信息 '违反了原子性,
二范式 (不存在部分依赖)
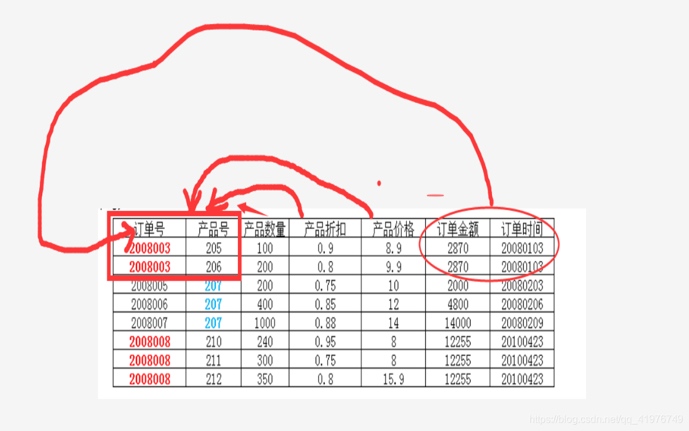
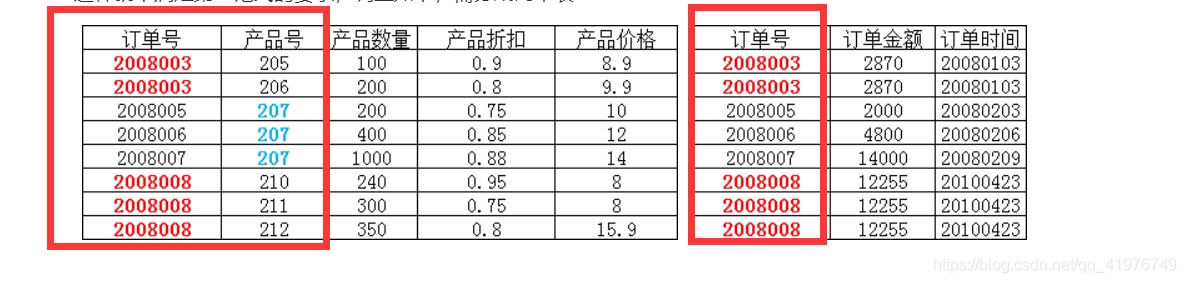
‘订单号’ 和 ‘产品号’ 是表的主键(主码),这两个字段一起决定了 ‘产品数量‘ ’产品折扣‘ ’产品价格‘ ,而订单金额和订单时间仅由订单号决定,不是由 主键(‘订单号’ 和 ‘产品号’)共同决定,所以 订单金额和订单时间是部份依赖于主键。
三范式 (不存在传递依赖)
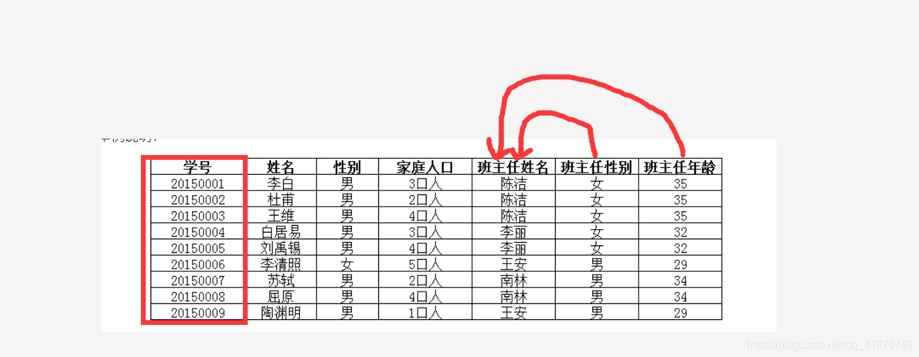
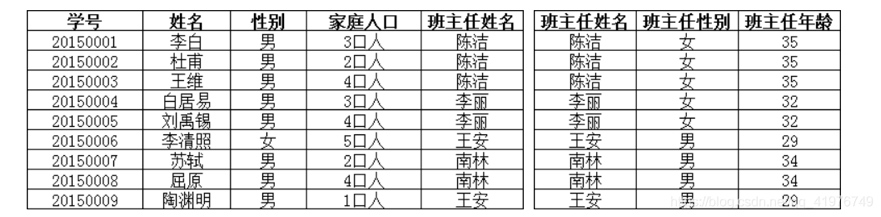
“班主任性别”和“班主任年龄”虽然间接依赖于学号(主键),但直接依赖的是“班主任姓名”。 注:间接依赖是属性与主键一一对应,但只是间接决定,不是直接决定,所以称为间接依赖
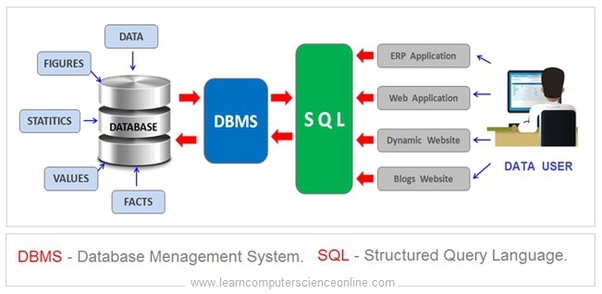
The database approach
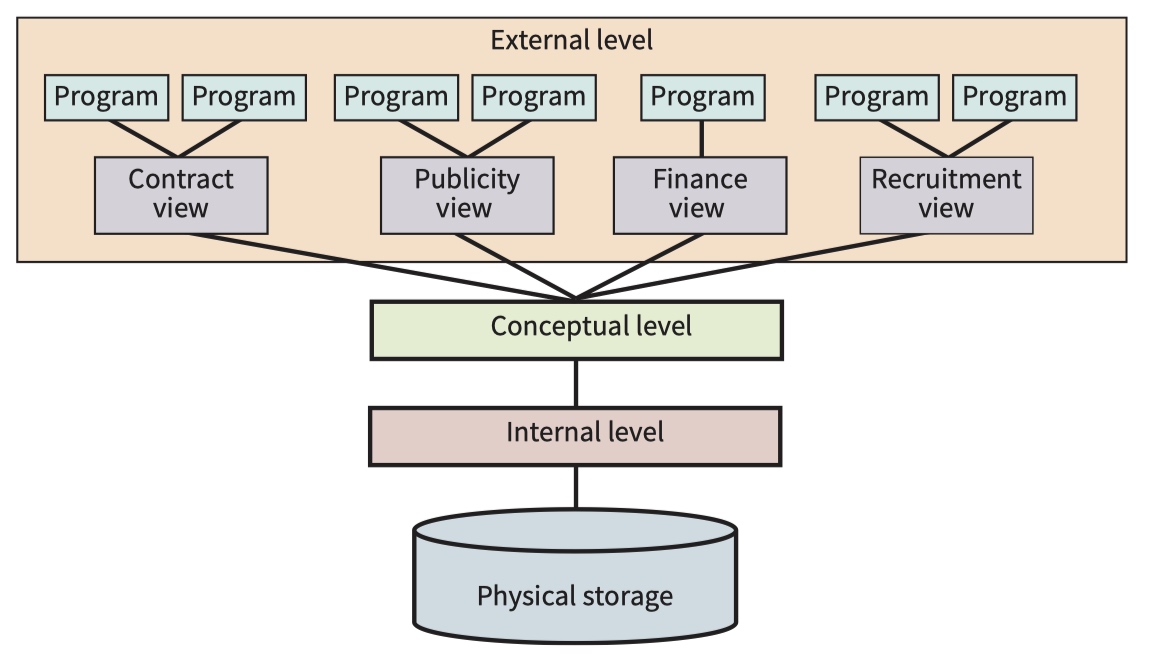
- the external level
- the conceptual level
- the internal level
The physical storage of the data is represented here as being on disk. The details of the storage (the internal schema) are known only at the internal level, the lowest level in the ANSI architecture. This is controlled by the database management system (DBMS) software.
At the next level, the conceptual level, there is a single universal view of the database. This is controlled by the database administrator (DBA) who has access to the DBMS. In the ANSI architecture the conceptual level has a conceptual schema describing the organisation of the data as perceived by a user or programmer. This may also be described as a logical schema.
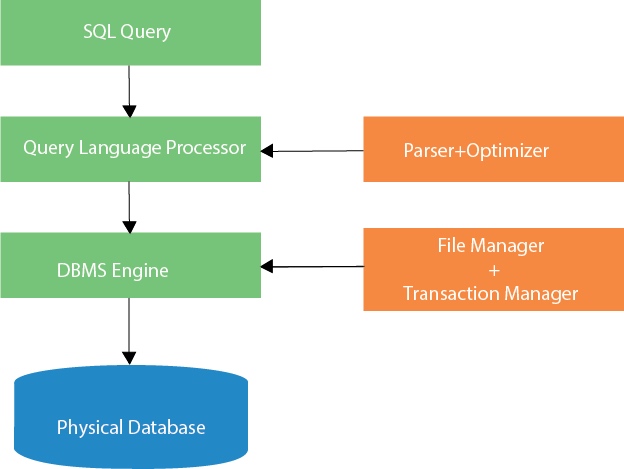
Structured Query Language (SQL)